
Tamas Szilagyi






Analytics databases more often than not contain a multitude of tables and views, depicting facts, dimensions or aggregate statistics. Responsibility for the underlying data pipelines traditionally belonged to Data Architects or Data Engineers. However modern tools like dbt are lowering the barrier to doing ETL.
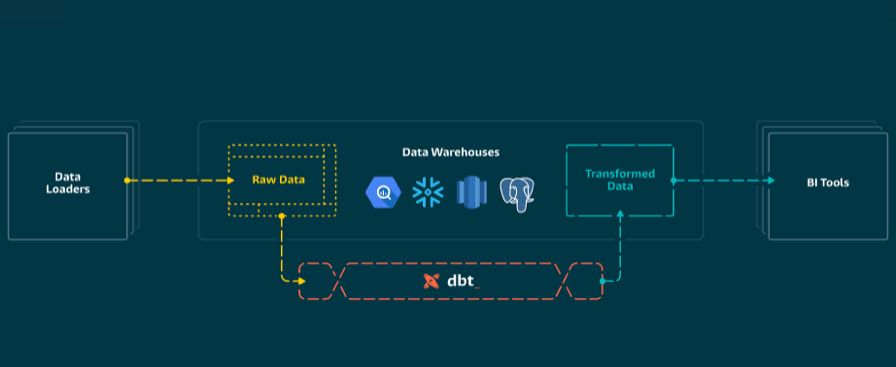
To use dbt, you only need to be familiar with SQL. The package relies on the Python templating language Jinja to enable nifty features like dependency graphs, macros or schema tests. Upon compilation, everything is translated into pure SQL and run on the databases execution engine. It is quite fascinating really how much you can do with such a minimalist tool.
In a previous post I talked about an approach to periodically load data from an API to BigQuery. Here, I’ll pick up from the BigQuery table containing daily response data from the 311 Service Calls dataset to illustrate dbt’s functionality. All the code from this post lives in a subdirectory of the same GitHub repo. Reading the previous post is by no means necessary to follow this one though.
The package can be installed using pip install dbt, and a new project initiated with dbt init [project-name], creating a directory structure containing the essentials. Currently dbt only supports Postgres, Redshift, Snowflake and BigQuery; and we need to configure the connection in ~/.dbt/profiles.yml first. For BigQuery, dbt needs to be able to create, modify or delete tables and views; that is to say it needs a service account with BigQuery admin roles attached. The downloaded .json file containing the required credentials can then be referenced inside profiles.yml under keyfile:.
311_data_pipelines: # name of profile
target: dev
outputs:
dev:
type: bigquery
method: service-account
project: dbt-sql
schema: dev
threads: 2
keyfile: /Users/tamas/dbt.json # service account credentials
prod:
type: bigquery
method: service-account
project: dbt-sql
schema: analytics
threads: 2
keyfile: /Users/tamas/dbt.json # service account credentialsIn addition, we can define different target schemas (in BigQuery this equals datasets) where tables and views are going to be materialized. It is recommended to have at least one dev environment besides the production tables for experimentation and prototyping.
The other configuration file is dbt-project.yml in the project directory. This file contains default settings for the project we can leave as is for the most part. Profile and project name should be set though, and we should also define default behavior of our models, the core building block in dbt.
name: 'test_package'
version: '0.0.1'
profile: '311_data_pipelines'
source-paths: ["models"]
analysis-paths: ["analysis"]
test-paths: ["tests"]
data-paths: ["data"]
macro-paths: ["macros"]
target-path: "target" # directory which will store compiled SQL files
clean-targets: # directories to be removed by `dbt clean`
- "target"
- "dbt_modules"
models:
test_package:
base:
enabled: true # run by defaultModels in dbt terminology refer to a collection of .sql files residing inside models/. Each file contains a select statement with some jinja-like expressions sprinkled on top. By default, the SQL queries are materialized as views, but can also be tables or incremental (tables). The latter means inserting new rows instead of recalculating the entire table on each run. Below is an example of an incremental model based on the source dataset. We’ll save this file as clean_data.sql.
{{ config(materialized='incremental') }}
select
datetime(created_date, "America/New_York") as datetime_created,
date(created_date, "America/New_York") as date_created,
time(created_date, "America/New_York") as time_created,
unique_key as id,
agency,
agency_name,
complaint_type,
descriptor as complaint_description,
resolution_description,
incident_zip as zip_code,
coalesce(intersection_street_1, street_name) as street,
borough
from `dbt-sql.311raw.data` --project_name.dataset.table
{% if is_incremental() %}
where datetime(created_date, "America/New_York") > (select max(datetime_created)
from {{ this }})
{% endif %}Materialization is either defined in the sql file or set in dbt-project.yml. On incremental runs, we need to filter for new rows using the is_incremental() macro. Each new table bears the name of the corresponding .sql file.
Creating new tables and views based on pre-existing objects implicitly builds a data pipeline. To chain together materlizations, we just reference other models with ref(). We could for example create a time-series of all noise complaints based on clean_data.
{{ config(materialized='incremental') }}
with clean_data as (
select *
from {{ ref('clean_data') }}
)
select
date_created,
count("*") as all_complaints
from clean_data
where complaint_type like "Noise%"
{% if is_incremental() %}
and date_created > (select max(date_created) from {{ this }})
{% endif %}
group by 1
order by 1 ascBy referencing tables this way, we define casual relationships making up a DAG.
Models can be run from the command line using dbt compile and dbt run. The former compiles all the jinja magic into actual SQL queries. The incremental models are for example expanded into a combination of merge, insert and delete statements depending on the database backend. The dbt run command runs all enabled models and materializes the results. Additional flags can be supplied to select or exclude specific models from running.
Not only can we use dbt’s built in macros, we can choose to write our own. This gives a lot of flexibility to abstract away unnecessary complexities. Like a rolling average function instead of a window statement:
{% macro rolling_avg(value_col, time_col, nr_rows) %}
AVG( {{ value_col }} )
OVER(ORDER BY {{ time_col }}
ROWS BETWEEN {{ nr_rows }} PRECEDING AND CURRENT ROW) AS rolling_avg
{% endmacro %}Saving it as rolling_avg.sql inside the macros/ directory, we can use it in any of our models.
with noises as (
select *
from {{ ref('noise_complaints') }}
)
select date_created, residential,
{{ rolling_avg('residential','date_created', 7) }}
from noisesOne of my favorite features of dbt is its testing framework. We can run two kind of tests, schema validation tests and data tests. There are schema tests included out of the box for uniqueness, missing values, relationships or accepted values.
These tests are effectively macros, which we could just as well write ourselves. It is in fact possible to create a dbt package consisting of macros only. In this sense dbt encourages the development of utility packages that can be shared and reused. A good example is dbt-utils, that among others contains some more tests. To use external packages, we need an extra packages.yml file in the package root directory listing dependencies.
packages:
- git: "https://github.com/fishtown-analytics/dbt-utils.git"In any case, schema tests need to be declared inside schema.yml in the models/ directory.
version: 2
models:
- name: clean_data
description: Cleaned up source data from the OpenData API.
tests:
- dbt_utils.recency: # recency test from dbt-utils
datepart: day
field: datetime_created
interval: 1
columns:
- name: datetime_created
description: Timestamp complaint was created.
tests:
- not_null # built-in missing value testAs for data tests, you’ll have to write your own. The idea is to have SQL queries that return results in case of an error. So let’s say we want to test equality of maximum dates between the 'clean_data' and the 'noise_complaints' tables. A test_maxdate.sql inside test/ could look as follows.
with clean as (
select max(date_created) as clean_date
from {{ ref('clean_data') }}
),
target as (
select max(date_created) as max_date
from {{ ref('noise_complaints') }}
)
select *
from target
full join clean
on target.max_date = clean.clean_date
where target.max_date IS NULL OR clean.clean_date IS NULLThe tests are run with dbt test, with additional flags for type of tests or specific models.
Creating and deploying documentation is even easier with the commands dbt docs generate and dbt docs serve. Descriptions like in the above schema.yml are optional, the static site will deploy with or without them. The result is an easy to navigate data dictionary that your teammates will thank you for. You can explore model schemas,
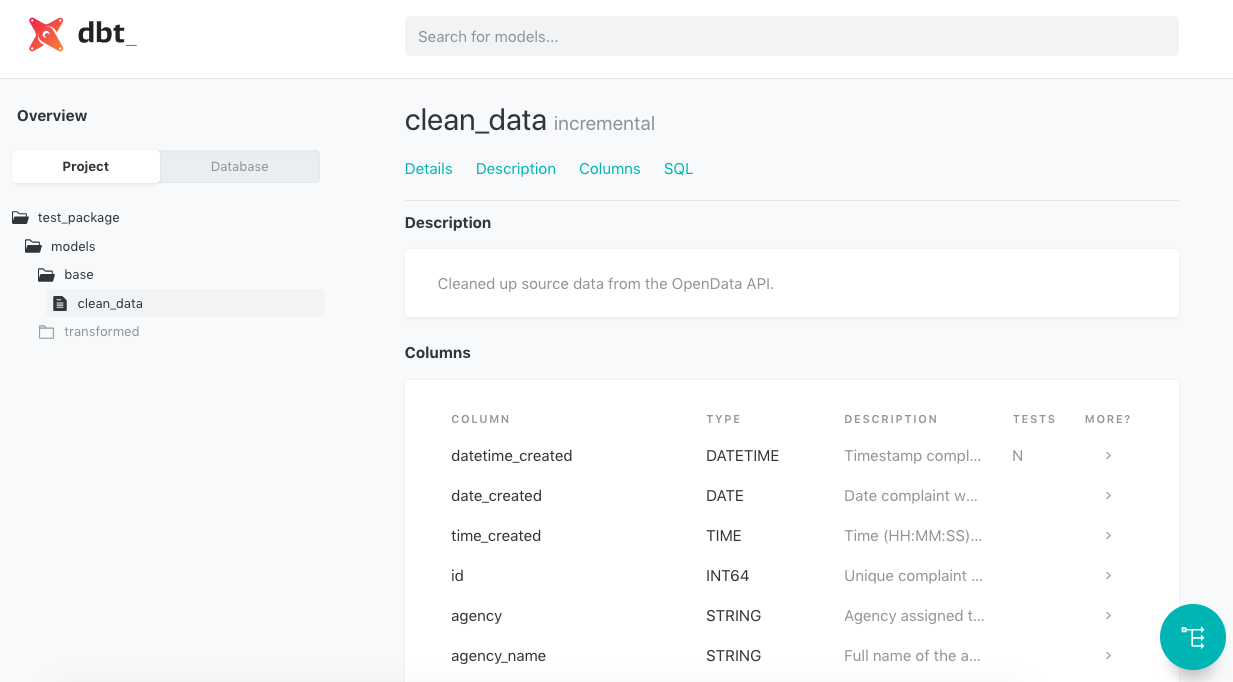
or finally inspect the created data pipelines.

While there is no native scheduling mechanism, dbt does provide a managed service called dbt Cloud you can sign up for. Besides scheduling jobs, you can view the logs of completed runs or render the documentation. The service is completely free of charge and is your best bet if you intend to use the dbt in production.
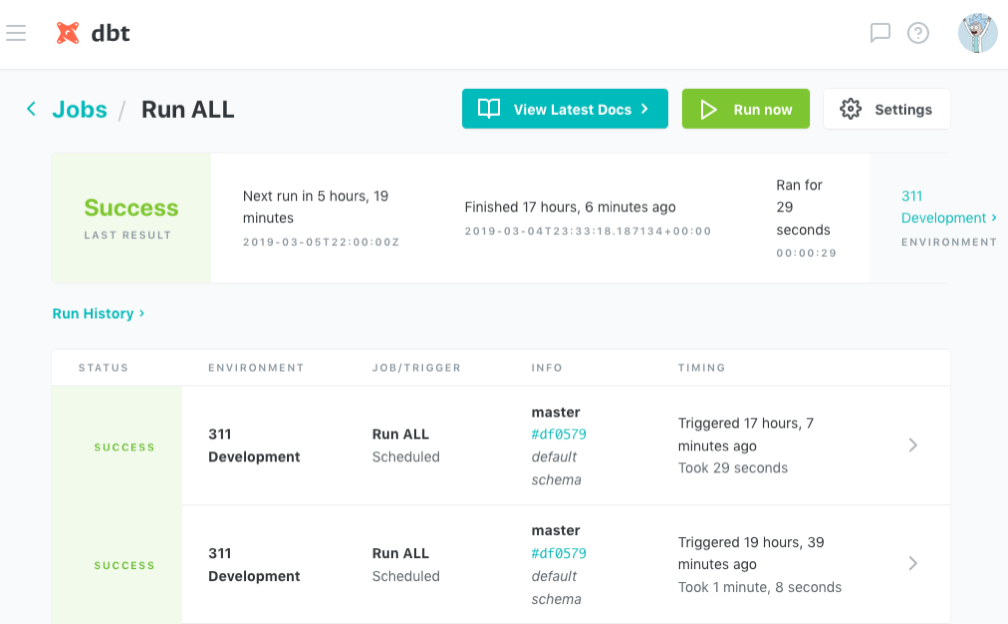
There is also an Airflow Operator that works in conjunction with dbt Cloud. But since dbt is in essence a command line tool, you can also just use cron.