
Tamas Szilagyi






For a recent project I needed to find an efficient way to extract data from API’s and load the response into a database residing in the cloud. It’s a fairly common use case, as most online platforms expose data via callable API’s. My personal goal was to introduce as little tooling and code as possible. After all, that’s the whole idea behind managed cloud services.
Using Google Cloud Platform, I came up with the following: 1. Cloud Function periodically calls API and saves .json to storage bucket. 2. BigQuery Transfer automatically picks up and loads .json file into a database table.
Sounds fairly simple, yeah. But unsurprisingly, there is a bit of configuration work along the way.
If you have never heard of them, you might have heard of AWS Lambda instead or perhaps Microsoft Azure Functions. They are what you’d call serverless compute architectures, but that’s slightly misleading as there are still servers involved. The idea is to focus on writing code and running functions in the cloud, and not worrying about the underlying infrastructure. Functions can be written in several languages - like Python - and are executed inside the language specific execution environment abstracted away from end-users.
To illustrate the workflow, I will use the 311 Service Calls in New York City dataset, updated daily and accessible through the Socrata Open Data API, which is in turn wrapped by a Python library called sodapy. To access the data from yesterday and save it as newline delimited .json files (this is what BigQuery expects) to Google Cloud Storage, we could write two functions:
import json
from datetime import date, timedelta
from sodapy import Socrata
from google.cloud import storage
def get_311_data(from_when):
socrata_client = Socrata("data.cityofnewyork.us",
APPTOKEN, USERNAME, PASSWORD)
results = socrata_client.get("fhrw-4uyv",
where = "created_date > '{}'".format(from_when),
limit = 8000)
return(results)
def fetch_and_write(data, context):
yesterday = date.today() - timedelta(1)
yesterday = str(yesterday)[:10]
payload = get_311_data(yesterday)
payload = '\n'.join(json.dumps(item) for item in payload) # transform to ND json
file_name = "311data_{}.json".format(yesterday.replace("-", ""))
storage_client.get_bucket(STORAGE_BUCKET) \
.blob(file_name) \
.upload_from_string(payload)Like most API’s, Socrata requires authentication (APPTOKEN, USERNAME, PASSWORD), which raises the first question of how to deal with secret variables when using cloud functions.
The naive approach is to supply secrets as environment variables during deployment. But this is no bueno because your tokens and passwords are now exposed in broad daylight in the function’s environment.
A better option is to encrypt your secret variables. This works fine, except that your cloud function now needs to know how to decrypt them. This can be accomplished with key management services like Cloud KMS, however the cost is additional complexity.
A third option is to save the secrets to a separate storage bucket, seal it off and grant exclusive privilege to the service account operating your cloud function. Objects on GCS are encrypted at rest by default and access can be tightly controlled by IAM roles. This is a good approach to go with.
When you enable cloud functions in the console, a new service account is automatically created. Using the development (or alpha) version of gcloud commands, we can also choose to associate a different service account with the cloud functions (see under Deployment). Either way, this service account needs to have the relevant roles assigned for privileged access.
# create bucket for secrets.json
gsutil mb gs://secrets-bucket
# set default access control to private
gsutil defacl set private gs://secrets-bucket
# upload secrets.json to bucket
gsutil cp secrets/secrets.json gs://secrets-bucket
# create new service account
gcloud iam service-accounts create cloud-funcs
# add read bucket/object roles to service account
gsutil iam ch serviceAccount:cloud-funcs@project-name.iam.gserviceaccount.com:legacyBucketReader gs://secrets-bucket
gsutil iam ch serviceAccount:cloud-funcs@project-name.iam.gserviceaccount.com:legacyObjectReader gs://secrets-bucket/secrets.jsonNow our cloud function will be able to read the secrets.json file from the secrets bucket, and retrieve the variables necessary for authentication during run time. A simple Python function to do the job could like this:
def load_creds():
blob = storage_client.get_bucket(SECRET_BUCKET) \
.get_blob('secrets.json') \
.download_as_string()
parsed = json.loads(blob)
apptoken = parsed['apptoken']
username = parsed['username']
password = parsed['password']
return apptoken, username, passwordIn the same vein, we also need roles to write .json files to a destination bucket. For example if the bucket is called gs://raw-data, the commands would be:
gsutil iam ch serviceAccount:cloud-funcs@project-name.iam.gserviceaccount.com:legacyBucketReader gs://raw-data
gsutil iam ch serviceAccount:cloud-funcs@project-name.iam.gserviceaccount.com:objectCreator gs://raw-dataThe second thing to decide before deploying serverless functions, is how to trigger them. On GCP, the two options are http requests or Pub/Sub messages; the latter being the default messaging system on Google Cloud. Since we want to schedule function runs with daily frequency, the recommended approach is to create a Pub/Sub topic (for example gcloud pubsub topics create cron-311) and periodically publish messages using Cloud Scheduler. This requires slight refactoring of the Python function though.
def fetch_and_write(data, context):
action = base64.b64decode(data['data']).decode('utf-8') # retrieve pubsub message
# ...
if (action == "download!"): # work is conditional on message content
payload = get_311_data(yesterday)
# ...Putting everything together inside a main.py file, the function is ready for deployment. Additional packages not included in the default Python run time are expected to be in a requirements.txt file in the same folder.
gcloud alpha functions deploy fetch_and_write --runtime python37 \
--service-account cloud-funcs@project-name.iam.gserviceaccount.com \
--trigger-topic cron-311 \
--set-env-vars SECRET_BUCKET=secrets-bucket,STORAGE_BUCKET=raw-dataNow we can head over to the Cloud Scheduler and create the trigger job:
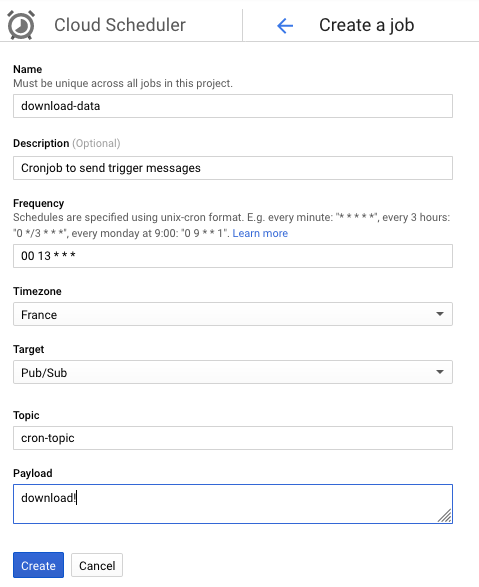
The second part of moving data into BigQuery is easily done with the BigQuery Data Transfer Service. It can load data into tables from storage buckets, but also from other Google platforms like AdWords or YouTube. Note that you need to be either owner of the project or have the bigquery.admin IAM role to be able create transfer jobs.
First though, we need to create a dataset inside BigQuery and add the empty destination table, accompanied by the schema (at least if we are loading .json files). I used the library bigquery-schema-generator to create it from a sample output of fetch_and_write().
The transfer job can be scheduled either from the command-line or in the UI, whatever you’re more comfortable with. The default frequency is every 24h.
bq mk --transfer_config \
--target_dataset=mydataset \
--display_name='My Transfer' \
--data_source=google_cloud_storage --params='{"data_path_template":"gs://raw-data/311data_{run_time-24h|\"%Y%m%d\"}.json","destination_table_name_template":"DATA","file_format":"JSON"}' The neat thing is that we can parametrise which files to transfer using custom logic based on run_time or run_date. The following snippet means that only json files stamped with yesterday’s date will be loaded on each run: 311data_{run_time-24h|"%Y%m%d"}.json. We can also provide additional parameters to ignore unknown fields, or delete objects from Google Storage once the job completed succesfully.