
Tamas Szilagyi






In the previous post, I shared an analysis of my Spotify listening history using R. In this post, I will discuss what came before having the data: collecting, cleaning and saving it. As the title suggest, we will even go a step further and automate the creation of a weekly top 10 playlist in Spotify using the very same dataset.
The main ingredient will be Luigi, a Python framework for workflow management Spotify open-sourced a couple of years ago. According to docs:
The purpose of Luigi is to address all the plumbing typically associated with long-running batch processes. You want to chain many tasks, automate them, and failures will happen. These tasks can be anything, but are typically long running things like Hadoop jobs, dumping data to/from databases, running machine learning algorithms, or anything else.
Designed for massive jobs, implementing Luigi on top of tiny little .json files might seem like a huge overkill, but the logic we will define won’t considerably differ from larger scale applications.
We can break down the pipeline into four tasks.
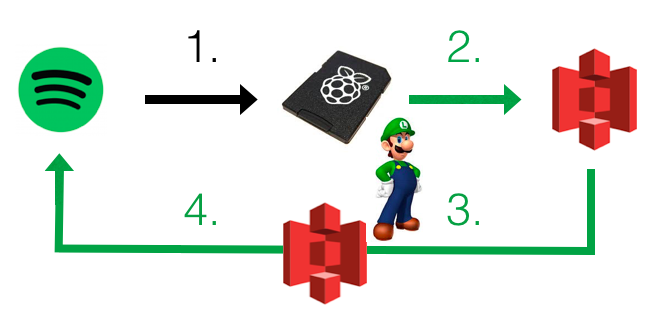
The initial step is to ping the API, and store the raw response as a .json file locally. We need to have the client_id, client_secret and a refresh_token to generate a temporary access token. Follow the Web API tutorial by Spotify to attain them. In turn, the access token is required to make calls to the API.
We start with two functions: One to generate the access_token using our credentials (I have them inside spotify_creds), and a second one to download our listening history, dumping the data in a new .json file every day. To make sure that the access token doesn’t expire, we’ll generate a new one with every call to the API.
I will store functions inside functions.py:
import requests
import json
import datetime
from spotify_creds import *
# Get access token
def access_token():
body_params = {'grant_type' : 'refresh_token',
'refresh_token' : refresh_token}
url = 'https://accounts.spotify.com/api/token'
response = requests.post(url,
data = body_params,
auth = (client_id, client_secret))
response_dict = json.loads(response.content)
accessToken = response_dict.get('access_token')
return accessToken
# Get most recent songs and append the response
# to a new json file every day
def download_data():
current_time = datetime.datetime.now().strftime('%Y-%m-%d')
filename = '/spotify/json/spotify_tracks_%s.json' % current_time
accesToken = access_token()
headers = {'Authorization': 'Bearer ' + accesToken }
payload = {'limit': 50}
url = 'https://api.spotify.com/v1/me/player/recently-played'
response = requests.get(url, headers = headers,
params = payload)
data = response.json()
with open(filename, 'a') as f:
json.dump(data['items'], f)
f.write('\n')Now, to make sure that I don’t miss any songs I have listened to, I will set up a cronjob to execute download_data() (that’s what logger.py contains) every three hours. We first make this file executable
chmod +x /spotify/logger.pyopen crontab,
crontab -eand add the following line to our list of cronjobs:
0 */3 * * * /usr/bin/python /spotify/logger.pyThe part with the numbers and *’s gives the scheduling logic. The second bit is the Python environment from which to call the script. If you prefer self-contained environments instead, then this will look something like /home/pi/miniconda/envs/name_of_env/bin/python on a Raspberry Pi using miniconda.
With raw data coming in, the next step is to store the result somewhere more robust than the SD card inside my Pi. Because we are pinging the API every three hours, we have files that contain 8 dictionaries of the last 50 tracks. Unless I listen to Spotify non-stop all day every day, there is going to be lots of redundancy because of duplicate records.
The function deduplicate() takes .json file we created above, and returns the deduplicated list of dictionaries containing only unique items according to the key played_at, which is the timestamp of each song played.
# Cleaner function to get rid of redundancy
def deduplicate(file):
result =[]
for line in file:
data = json.loads(line)
result.extend(data)
result = {i['played_at']:i for i in result}.values()
return resultFrom this point onwards, we are going to switch to using Luigi. The main building block is a Task, which usually consists of three methods:
requires(): What other task the current one depends on.run(): What is our tasks going to do, usually some function.output(): Where will the result be stored.In turn, output() will end up in the require() method of a consecutive task. This builds a dependency graph between tasks. Let’s jump right in, and look at how we apply this logic:
import luigi
from datetime import date, timedelta
from functions import *
# External task at the bottom of our dependancy graph,
# only looks to see if output of cronjob exists,
# by default from yesterday.
class local_raw_json(luigi.ExternalTask):
date = luigi.DateParameter(default = date.today()-timedelta(1))
def output(self):
return luigi.LocalTarget('spotify/json/spotify_tracks_%s.json' %
self.date.strftime('%Y-%m-%d'))The first task local_raw_json is an External Task with only an output() method. This task does not run anything and does not depend on anything. It simply confirms the existence of a file, namely the output from our cronjob. Luigi allows for parameterization of tasks, so we define a date parameter with the default value yesterday. We pass this to the output() method to look for the file with the correct date.
External tasks with no dependencies are common first steps, especially if we are relying on an external datadump somewhere else.
import json
from luigi.s3 import S3Target, S3Client
# Task that runs our deduplicate() on local file
# and writes the output to S3 bucket.
class spotify_clean_aws(luigi.Task):
date = luigi.DateParameter(default = date.today()-timedelta(1))
def requires(self):
return self.clone(local_raw_json)
def run(self):
with self.input().open('r') as in_file:
data = deduplicate(in_file)
with self.output().open('w') as out_file:
json.dump(data, out_file)
def output(self):
client = S3Client(host = 's3.us-east-2.amazonaws.com')
return S3Target('s3://myspotifydata/spotify_tracks_%s.json' %
self.date.strftime('%Y-%m-%d'),
client=client)The second tasks is spotify_clean_aws. This is where we run the deduplicate() function defined earlier and write the output to an AWS S3 bucket. In contrary to the first task, all three methods are present:
Require that the raw json file exists, and also clone() the parameters from the first task. This way the same date parameter will be passed to both tasks.
Run the function deduplicate() on the input file and save the result as a .json.
Output the result of the task to S3. Luigi has built-in support for AWS S3 that uses boto3 under the hood. To connect, we need to have AWS credentials. They usually reside under ~/.aws/credentials, if you have run aws configure in the Terminal before:
[default]
aws_access_key_id = YOUR_ACCESS_KEY
aws_secret_access_key = YOUR_SECRET_KEY It is also possible to pass them explicitly to S3Client() however.
With the data deduplicated and safely stored in the cloud, we can now parse the files, selecting a handful of fields from the response. Because nobody ever gets excited about ETL code, I will omit the contents of parse_json() here. It is suffice to say that we get a more compact result than what I used in the previous post. An example record from the resulting dictionary will look like this:
{"played_at": "2017-04-22T18:49:54.108Z",
"track_name": "Symphony No. 5 In C Minor Part 1",
"duration_ms": 485293,
"type": "track",
"artist_id": ["2wOqMjp9TyABvtHdOSOTUS"],
"explicit": false,
"uri": "spotify:track:0ZN01wuIdn4iT8VBggkOMm",
"artist_name": ["Ludwig van Beethoven"],
"track_id": "0ZN01wuIdn4iT8VBggkOMm"}You can still find all the code for parse_json() function (and all the others) on my Github.
Secondly, we’ll merge a week worth of data and store the intermediate result on S3. With these ingredients, we define our third Luigi Task: spotify_merge_weekly_aws :
# Task that merges the 7 daily datasets,
# parses relevant fields, deduplicates records
# and stores the result in S3.
class spotify_merge_weekly_aws(luigi.Task):
date = luigi.DateParameter(default = (date.today()-timedelta(8)))
daterange = luigi.IntParameter(7)
def requires(self):
# take data from the 7 days following date param (8 days prior to current date by default)
return [spotify_clean_aws(i) for i in [self.date + timedelta(x) for x in range(self.daterange)]]
def run(self):
results = []
for file in self.input():
with file.open('r') as in_file:
data = json.load(in_file)
parsed = parse_json(data)
results.extend(parsed)
# merging of daily data creates dupe records still
result = {v['played_at']:v for v in results}.values()
with self.output().open('w') as out_file:
json.dump(result, out_file)
def output(self):
client = S3Client(host = 's3.us-east-2.amazonaws.com')
return S3Target('s3://myspotifydata/spotify_week_%s.json' %
(self.date.strftime('%Y-%m-%d') + '_' + str(self.daterange)),
client=client)As a last step, we aggregate the weekly data and fill up our playlist on Spotify. These are the last two functions we need to define. Not to complicate things too much, I am simply going to create a top 10 of my most listened to tracks between 7am and 12pm. Sort of a morning playlist.
# This function takes a list of track uri's
# to replace songs in my morning playlist
# and returns the status code of the put request.
def replace_tracks(tracks):
url = 'https://api.spotify.com/v1/users/1170891844/playlists/6a2QBfOgCqFQLN08FUxpj3/tracks'
accesToken = access_token()
headers = {'Authorization': 'Bearer ' + accesToken,
'Content-Type':'application/json'}
data = {"uris": ','.join(tracks)}
response = requests.put(url, headers = headers,
params = data)
return response.status_code
# This function reads in the weekly dataset
# as a pandas dataframe, outputs the list of
# top ten tracks and feeds them to replace_tracks()
def create_playlist(dataset, date):
data = pd.read_json(dataset)
data['played_at'] = pd.to_datetime(data['played_at'])
data = data.set_index('played_at') \
.between_time('7:00','12:00')
data = data[data.index > str(date)]
# aggregate data
songs = data['uri'].value_counts()\
.nlargest(10) \
.index \
.get_values() \
.tolist()
# make api call
res_code = replace_tracks(songs)
return res_codeNow we wrap the above inside our last Luigi Task, spotify_morning_playlist:
# Task to aggregate weekly data and create playlist
class spotify_morning_playlist(luigi.Task):
date = luigi.DateParameter(default = (date.today()-timedelta(8)))
daterange = luigi.IntParameter(7)
def requires(self):
return self.clone(spotify_merge_weekly_aws)
def run(self):
with self.input().open('r') as in_file:
res_code = create_playlist(in_file, self.date)
# write to file if succesful
if (res_code == 201):
with self.output().open('w') as out_file:
json.dump(res_code, out_file)
def output(self):
client = S3Client(host = 's3.us-east-2.amazonaws.com')
return S3Target('s3://myspotifydata/spotify_top10_%s.json' %
(self.date.strftime('%Y-%m-%d') + '_' + str(self.daterange)),
client=client)I have put all of the tasks in a file named tasks.py. Luigi does not provide a scheduling mechanism out of the box, so we’ll trigger the tasks from crontab instead. For example every Monday at 7AM:
0 7 * * 1 /usr/bin/python /spotify/tasks.py spotify_morning_playlistNote that we should have the Central Scheduler running in the background for the above to execute. The neat thing is that we only need to trigger the last task, and then Luigi considers all the dependencies and runs them if needed (ie. if the target file does not exists). Additionally, Luigi has a real nice GUI running on localhost:8082, where we can visualise the complete dependency graph and monitor the progress of our tasks:
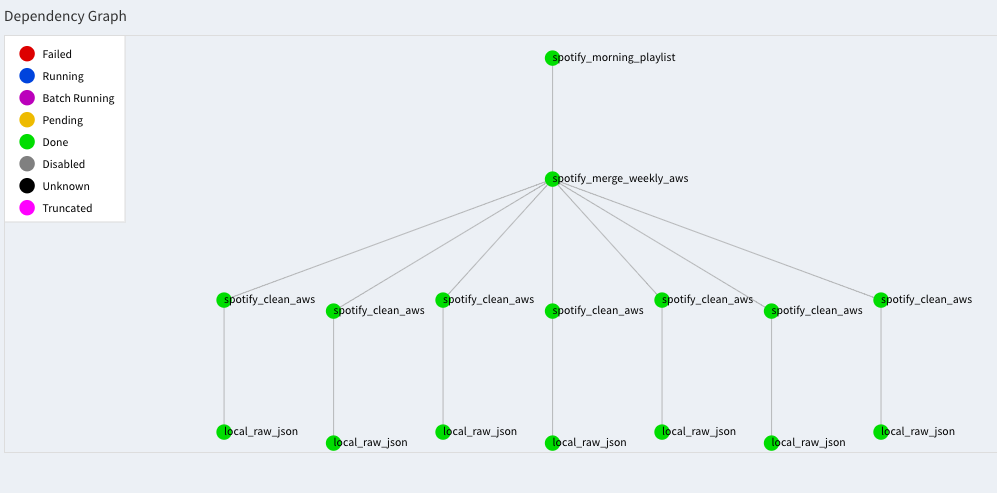
If nothing fails, the tracks in the below playlist get updated every Monday morning:
I have tried to give a simple, yet fully reproducible example of how to set up a workflow using Luigi. It is important to note that building data pipelines for production systems does require a little more effort. To name a few shortcomings of the above: We haven’t defined logging, we didn’t clean up our original files containing the raw response data, and it is very likely that the same tracks will end up in this playlist on consecutive weeks. Not something you would want to happen to your Discover Weekly for example.
If you want to learn more about Luigi, I encourage you to read the documentation and most of all start experimenting on personal projects. I find that is always the best way to learn new skills.
On the other hand, we could also create playlists that are more useful to us than a simple top 10 playlist. What if we took artists we listen to the most, and automatically put their songs not in our listening history yet in a new playlist. It is perfectly possible, and probably more valuable to us as users. We just need to write a couple new functions, plug them into a similar Luigi pipeline as above and let it do the work for us.